http://ko.sunningview.com/article/5325 퍼옴.
메모리 구조를 보장하기 위해 래치 래치 일관성 경량 동기화 메커니즘 SQL Server 엔진은 무엇입니까. 이러한 인덱스, 데이터 페이지 (예 : 비 잎 수준 인덱스 페이지 등) 내부 구조 등.
< 래치는
래치는 메모리 구조를 보장하기 위해 일관성있는 경량 동기화 메커니즘 SQL Server 엔진이 무엇인지입니다. 이러한 인덱스, 데이터 페이지 (예 : 비 잎 수준 인덱스 페이지 등) 내부 구조 등. SQL Server는 I / O 래치 보호가 버퍼 풀 페이지에로드되어 있지 않은, 사용 비 버퍼 래치 보호 메모리 내부 구조와, 버퍼 래치 보호 페이지 버퍼 풀을 사용합니다.
- 버퍼 래치 : 작업자 스레드 전에 페이지가 버퍼 풀에 액세스 할 때, 먼저이 페이지에 래치 받아야합니다. 주로 사용자 개체 및 시스템 개체 페이지를 보호하기 위해 사용된다. 근로자가 요구하는 액세스 페이지가 버퍼 풀에없는, 그것은 풀에 해당하는 페이지를로드 스토리지 시스템에서 비동기 I / O를 보낼 것입니다 : _ *
- I / O를 래치 형 성능 PAGELATCH을 기다립니다. 이 과정은, 해당 페이지의 I / O 래치 얻을 호환 래치 풀로 동일한 페이지를로드 다른 스레드를 방지한다. 유형 성능 PAGEIOLATCH을 기다립니다 _ *
- 비 버퍼 래치 : 버퍼 풀 페이지 외부에서 내부 메모리 구조를 보호하기 위해 사용. 유형 성능있는 Latch_XX을 기다립니다.
래치 인보다는 전체 트랜잭션을 유지하는 로크로만 대응 페이지 또는 내부 구조의 동작 동안 유지. 예를 들어, WITH NOLOCK 테이블을 조회하여. 쿼리 프로세스는 테이블의 모든 수준에서 공유 잠금을 획득하지 않지만 데이터 페이지 전에 읽을 수 있습니다, 당신은 얻을이 페이지를 래치 할 필요가있다.
=
래치 모드
래치 잠금 장치와 함께, 그것은 SQL 서버 엔진 동시성 제어의 일부입니다. 높은 동시성의 경우 래치하는 것은 피할 수없는 경쟁 환경. SQL 서버는 다른 마무리 대상 리소스를 액세스하기 위해 래치 대상 리소스를 해제 할 때까지 기다릴 호환 개의 래치에게 요청 스레드를 강제로 호환 모드를 사용한다.
래치 모드 5 종류가 있습니다 :
- KP - 래치 구조 기준에 의해 파괴되지 않도록 유지 SH
- - 필요한 경우 공유 래치는 데이터 페이지를 읽고
- UP - 업데이트 래치 데이터 변경 페이지가 필요할 때
- EX - 필요가 데이터 페이지를 작성하는 경우 독점 래치 전용 모드가 주로 사용됩니다
- DT - 데이터가 필요
래치 모드 호환성에 의해 참조 될 때 래치 구조적 손상을 파괴, Y는 N을 나타내고, 호환 나타냅니다 호환되지 않습니다 :
| KP | SH | UP | EX | DT |
| Y | Y | Y < /td> | Y | N |
| Y | Y | Y | N | N |
| Y | Y | N < /td> | N | N |
| Y | N | N | N | N |
| N | N | N < /td> | N은 | N |
& LT/div>
- 래치 경합에 미치는 영향 요인
| 요소 | SLEEP_TASK |
| 논리적 CPU | 어떤 멀티 코어의 과도한 사용을 고백 래치 경합 시스템이 나타납니다. 래치 경합은 시스템의 허용 수준, 사용 16 이상의 코어의 대부분을 초과합니다. |
| 건축 설계 및 액세스 모드 | 크기 B 트리 깊이, 인덱스, 밀도 및 페이지 디자인, 데이터 액세스 모드 동작이 과도 래치 경합으로 이어질 가능성이 높다 |
| 응용 프로그램 계층 동시성 높은 | 래치 경합 애플리케이션 층의 가장 높은 동시 요청을 동반한다. |
| 레이아웃 데이터베이스 논리 파일 | 논리 파일 배치함으로써 경쟁 래치의 정도에 영향을 미치는 레이아웃, (등 PFS, GAM, SGAM, IAM, 등) 분배 장치 구조에 영향을 미친다. 이것의 가장 유명한 예는 다음과 같습니다 자주 PFS 페이지의 tempdb의 경쟁의 결과로 작성하고 임시 테이블을 삭제할 때 |
| I / O 서브 시스템의 성능 | PAGEIOLATCH는 SQL 서버의 I / O 서브 시스템을 기다리는 많은 의미 기다립니다 . |
더 얕은 B 트리 많은 수의. 페이지 분할을 수행 할 때, 우리는 모든 수준에서 B- 트리 EX 래치를 수정 SH 래치를 얻고 데이터의 모든 페이지에서 얻을 필요가있다. 삽입의 경우에 발생하는 B- 트리 루트 페이지 분할로 매우 높은 동시성뿐만 아니라, 매우 가능성이 리드를 삭제합니다. 루트 페이지 분할 비 버퍼 래치로 이어질 것입니다 : ACCESS_METHODS_HBOT_VIRTUAL_ROOT을.
진단 래치 경합
주요 진단 방법과 도구는 다음과 같습니다 :
- 관측 성능 모니터 CPU 사용률 및 SQL Server 대기 시간이 있는지 두 개의 관련 결정합니다.
- 은 DMV 래치 특정 유형의 자원 경쟁에 의해 발생하기.
- 특정 비 버퍼 래치 경합 진단, 또한 SQL 서버 프로세스의 메모리 덤프 파일을 획득하고 분석하기 위해 함께 윈도우 디버깅 툴을 결합해야.
래치 경합 정상적인 활동이고, 래치 경합이 발생하는 자원에 대한 액세스를위한 타겟 및 기다리는 시간이 시스템 처리량에 영향을 미치지 만하면 해로운 것으로 믿어졌다. 경합의 적당한 정도를 확인하기 위해, 함께 성능, 시스템 스루풋 처리, IO 및 CPU 자원 분석의 조합을 필요로한다.
[
래치 경합으로 시간이 애플리케이션 성능에 미치는 영향
1. 페이지 래치 평균 대기 시간의 성장과 증가 시스템 처리량을 처리 계약 을 측정 기다립니다. 페이지 래치 평균 대기 시간이 시스템 처리량을 증가시키고, 특히 성장 버퍼 래치 대기 시간을 일관된 성장을 관리하는 저장 시스템의 응답 시간을 초과하는 경우
, 현재 대기중인 작업을 확인할 sys.dm_os_waiting_tasks 사용해야한다. 또한 관찰 시스템 활동 및 부하 특성의 조합을 필요로한다. 일반 공정 진단 :
- 사용 "쿼리 세션 ID 발주 sys.dm_os_waiting_tasks"스크립트 또는 "계산 대기 시간 동안"스크립트는 현재 작업하고 평균 대기 시간 상황 래치 대기를 관찰합니다.
- 사용 "QueryBufferDescriptorsToDetermineObjectsCausingLatch"스크립트가 경합 (인덱스 및 테이블)의 발생 위치를 결정합니다.
- MSSQL이 % 인스턴스 이름 % StatisticsPage 래치 WaitsAverage 대기 시간 또는은 sys.dm_os_wait_stats가 관찰 된 평균 대기 시간 페이지 래치 방문 기다립니다 관찰 할 성능 카운터를 사용.
(o.name), i.name, 총 대기 시간의 비즈니스 피크 대기 시간 래치 비율 (2).
래치는 비율이 하중 증가에 따라 선형 적으로 증가 대기 시간을 경우, 경합이 성능에 영향을 래치 할 수있다, 우리는 최적화 할 필요가있다. 하여 대기 통계 성능 수는 페이지와 비 페이지 래치가 상황을 기다려야 관찰했다. 그런 다음 CPURAMIONetwork 처리량 관련 카운터와 비교. 예를 들어, 거래 / 분파 및 배치 요청 / 초를 사용하여 자원 활용도를 측정합니다. 이 마지막 인스턴스 시작 (또는 비워) 이후 기록이기 때문에
은 sys.dm_os_wait_stats는 데이터를 기다린 후, 기다리는 대기 시간의 모든 유형을 포함하지. 또한 DBCC SQLPERF을 할 수 있습니다 ( '은 sys.dm_os_wait_stats는', '클리어') 수동으로 비 웁니다. 시간은 sys.dm_os_wait_stats 데이터를 취할 피크 사업하기 전에, 다음, 비즈니스에서 피크를 취할 차이를 계산합니다.
-
3. 증가없이 시스템 처리량 처리 (또는 감소), 응용 프로그램이로드가 무거운, SQL 서버에서 사용할 수있는 CPU 증가하면서 .
높은 동시성 및 멀티 CPU 시스템에서, 클러스터 된 인덱스가 자려 동시 삽입 유사 지금 등의 종류가 발생할 것이다 : CPU는 수를 증가 및 대기 래치 페이지가 증가하면서 시스템 스루풋이 저하된다.
나
4. 부하의 성장을 적용 할 때 CPU 사용률이 증가하지 않았다.
CPU 사용률 성장 나타내는 SQL 서버 리소스 (래치 경합 성능)을 기다리고 애플리케이션로드와의 동시가 없을 때.
으로
쿼리 현재 래치
현재 실시간 대기 정보 볼 수 있습니다 다음 쿼리. * 및 PAGEIOLATCH_ * 버퍼 래치가 기다리고 PAGELATCH_하는 wait_type.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type 그대로 last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id , wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks 중량
가입 바로 sys.dm_exec_sessions ES ON wt.session_id = < /span> es.session_id
가입 sys.dm_exec_requests 어 ON wt.session_id = er.session_id
여기서 es.is_user_process es.is_user_process OBJECT_ID '
1 와 wt.wait_type ))클러스터 < /span> '
ORDER ' ' ORDER 에 o.type
, er.last_wait_type 그대로 last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id , wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks 중량
가입 바로 sys.dm_exec_sessions ES ON wt.session_id = < /span> es.session_id
가입 sys.dm_exec_requests 어 ON wt.session_id = er.session_id
여기서 es.is_user_process es.is_user_process OBJECT_ID '
1 와 wt.wait_type ))
ORDER ' ' ORDER 에 o.type
wt.wait_duration_ms
DESC
| OBJECT_ID | ' |
| 쿼리 열을 리턴으로 설명 : | 열 |
| 설명 | 의 session_id |
| 세션 ID 작업이 속한 | Wait_type |
| 현재 대기 유형 | Last_wait_type |
| 마지막 대기 유형은 | Wait_duration_ms |
| 대기 시간 합계 (MS)의 대기 유형을 기다립니다 | Blocking_session_id |
| 현재 차단되는 세션 ID | Blocking_exec_context_id |
현재 발생 한다, '버퍼'순서 ID
Resource_description
특정 대기
| 다음 쿼리는 반환 비 버퍼 래치 정보 | 을 선택 * sys.dm_os_latch_stats를에서 latch_class & LT의 리소스 작업 wait_time_ms에 의해 DESC |
| 는 열 지침을 반환 : | 열 |
| 설명 대기 시간 | Latch_class |
| 래치 유형 | Waiting_requests_count |
| 현재 래치 유형이 발생 < /div> | Wait_time_ms |
현재 래치 유형 합 대기 시간을 발생
Max_wait_time_ms
현재 래치 형 발생한 가장 긴
=
래치 일반적인 시나리오 경합을 <기다리는 동안/div>
데이터 마지막 페이지 삽입 경합
, 그것은 경쟁을 래치 될 수 있습니다 . 이 시나리오에서
테이블은 거의 아카이브 삭제 및 업데이트 작업 할 때를 제외하고 적용되지/div> ![]()
인덱스에 데이터를 삽입 :
1 B- 트리를 검색, 새로운 페이지로 이동하여 저장하는 것입니다
이 페이지 플러스 전용 래치 (PAGELATCH_EX)에 2 ,. 다른 작업이 동시에이 페이지를 수정하지 마십시오. 모든 비 리프 페이지 플러스 공유 래치 (PAGELATCH_SH).
때때로 페이지가 직접 비 리프 페이지에 영향을 개로 나누어 독점 래치, 비 리프 페이지에.
3.이 행이 변경되었음을 나타냅니다 로그 파일에 기록을 작성
4. 페이지에 새 행을 작성하고 더러운 페이지로 표시 5. 릴리스 모든 래치. 线程获取到页上排他Latch。假设A获取EX Latch,则B就需要等待。则B就会在 sys.dm_os_waiting_tasks表现出等待类型为PAGELATCH_EX的等待。
, 새로운 라인이 페이지는 가득 찰 때까지, B- 트리의 마지막 페이지에 삽입됩니다. 높은 동시로드, 그것은 B- 트리가 가장 오른쪽 페이지 경합이다 집계 및 비 클러스터형 인덱스로 이어질 것입니다. 일반적으로이 메인 페이지와 밀도 인덱스를 삽입하는 동시성 경합이 발생합니다. sys.dm_db_index_operational_stats으로 상황은 라스 페이지 경합와 B 트리 리프 페이지에게 중앙 아프리카 래치 경합을 관찰 할 수있다.
예를 들어
동시에 스레드와 스레드 B는 새 행 (예 : 1999 등) Last (마지막)로 삽입합니다. 논리적으로, 둘 다 동시에 해당 행 수준의 행 마지막 페이지 단독 잠금을 얻을 수 있습니다. 그러나, 메모리의 무결성을 유지하기 위해
- 하나는 하나의
- 스레드 페이지에 배타적 래치를 획득 할 수있다. 이 EX 래치를 얻기 가정, 다음 B 기다릴 필요가있다. 그런 다음 B가 sys.dm_os_waiting_tasks에 전시된다 타입 PAGELATCH_EX 대기를 기다립니다. 작은 테이블의 임의 삽입에 리드
- (32)
이 클러스터되지 않은 인덱스 래치 경합
임시 큐 구조는 일반적으로이 시나리오를 발생으로 테이블을 사용합니다. 다음 조건 (EX와 SH 포함) 래치 경합이 발생할 수 있습니다 사항 :
높은 동시 INSERT, DELETE, UPDATE 및 Operations (작업) 페이지 밀도, 좁은 라인 테이블의 행의 수는 적게, 그래서 B-나무도 등급 2-3 인덱스 깊이 얕은입니다. 페이지 분할을 일으킬 가능성이 INSERT의 임의의 실행의 를 필터링 ( o.name), i.name, 지수는 스크립트 다음 테이블의 깊이를 관찰 할 수있다 : 선택 o.name 으로 - 모든 인덱스 키 범위에 기존 데이터 분포를 사용하는 열은 테이블 ] , i.name 으로
SomeInt [ 인덱스 ] HashValue INDEXPROPERTY 으로 변경
OBJECT_ID 테이블 ' indexDepth + [ INDEXPROPERTY 차 TINYINT INDEXPROPERTY OBJECT_ID (o.name), i.name, ' isClustered
( SomeInt 등 깊이, 변경 리프 수준을 계산하지 않습니다보고 클러스터 된 인덱스 깊이 테이블 [ 행 ] , i.origFillFactor차 모드 2 이동 CPU 코어는 TransactionId 번호 제 키 인덱스로 모듈로 사용하여, 삽입 작업이보다 균일하게 분산 된 테이블로된다. ( [ 행 ]
, i.origFillFactor ( BIGINT [ FILLFACTOR ] 그대로 의 경우 INT INDEXPROPERTY
( INT (o.name), i.name 널 (null) isClustered ] <그 속도를 대량로드 기술을 사용하는 것이 좋습니다span> 다음 때 '
1 (32) 다음 NULL ' - o.id 때 i.id
0 기능 [ 12 -
클러스터되지 않은 latch_contention_table 다른 )
와 통계
' 끝 - 표 입력 할 때 < /span> IX_Transaction_ID
SYSINDEXES에서 나는 가입 sysobjects의 O hash_col ' = '
여기서 ) = ( ' U '와 ') 파티션 구성표 )), ( (o.name), i.name, NOT isHypothetical '
) 의 사용을 필요로한다. 제 키의 지수는 일반적으로 선택된 열 또는 해시 열을 산출하고, 다른 열을 형성하도록 함께 결합 된 후 일부 열을 식별한다. 유일한 ID 열 값이 너무 과도 키 간격의 결과는 데이터 테이블의 물리적 구조를 만들기 때문에 열 열화를 이용한 해시 연산이 우수하다. 이하 해시 계산 열 인덱스 키 범위가 있지만, 래치 경합 INSERT 부하를 분산시키기 위해 감소된다하더라도, 충분하고있다. 예를 들어, 판매 시스템은하면 해시 값 모듈로서 CPU 코어 STORE_ID 번호를 사용할 수있다. 0 ' 가상 인덱스 ') INDEXPROPERTY OBJECT_ID ' isStatistics
' =
SomeInt [ 인덱스 ] HashValue INDEXPROPERTY 으로 변경
OBJECT_ID 테이블 ' indexDepth + [ INDEXPROPERTY 차 TINYINT INDEXPROPERTY OBJECT_ID (o.name), i.name, ' isClustered
( SomeInt 등 깊이, 변경 리프 수준을 계산하지 않습니다보고 클러스터 된 인덱스 깊이 테이블 [ 행 ] , i.origFillFactor
, i.origFillFactor ( BIGINT [ FILLFACTOR ] 그대로 의 경우 INT INDEXPROPERTY
( INT (o.name), i.name 널 (null) isClustered ] <그 속도를 대량로드 기술을 사용하는 것이 좋습니다span> 다음 때 '
1 (32) 다음 NULL ' - o.id 때 i.id
0 기능 [ 12 -
클러스터되지 않은 latch_contention_table 다른 )
와 통계
' 끝 - 표 입력 할 때 < /span> IX_Transaction_ID
SYSINDEXES에서 나는 가입 sysobjects의 O hash_col ' = '
여기서 ) = ( ' U '와 ') 파티션 구성표 )), ( (o.name), i.name, NOT isHypothetical '
) 의 사용을 필요로한다. 제 키의 지수는 일반적으로 선택된 열 또는 해시 열을 산출하고, 다른 열을 형성하도록 함께 결합 된 후 일부 열을 식별한다. 유일한 ID 열 값이 너무 과도 키 간격의 결과는 데이터 테이블의 물리적 구조를 만들기 때문에 열 열화를 이용한 해시 연산이 우수하다. 이하 해시 계산 열 인덱스 키 범위가 있지만, 래치 경합 INSERT 부하를 분산시키기 위해 감소된다하더라도, 충분하고있다. 예를 들어, 판매 시스템은하면 해시 값 모듈로서 CPU 코어 STORE_ID 번호를 사용할 수있다. 0 ' 가상 인덱스 ') INDEXPROPERTY OBJECT_ID ' isStatistics
' =
0
- 필터링 통계 위해
의
- o.name
래치 PFS 경합 페이지
이 그것은
병목
상황을 할당에 속한다. PFS 레코드 공간 이용 데이터 페이지. 바이트 (바이트) 페이지의 PFS 페이지의 사용을 나타냅니다을 사용합니다. PFS 페이지 정도로 모든 8088 개의 데이터 페이지가 PFS 페이지가있을 것이다, 8088 데이터 페이지를 나타낼 수있다. 두 번째 페이지의 데이터 파일 PFS 페이지이다 (된 pageid = 2). 새 개체 또는 데이터 조작을위한 공간을 할당해야하는 경우
, SQL Server는 SH 래치를 사용할 단순한 대상 페이지가 있는지 여부를 확인 PFS 페이지에 사용할 수 있습니다. 존재하는 경우, 그것은 PFS 래치를 얻고, 해당 페이지 공간 사용량 정보를 업데이트한다. 유사한 프로세스는 SAM, GSAM 페이지에 발생합니다. 멀티 CPU 시스템, 파일 그룹, 몇 데이터 파일, 과도한 PFS 페이지 요청에, 그 래치 경합을 초래할 수있다. tempdb의 가장자리 장면은 몇 가지 비교적 흔한 것입니다. PFS 나 SGAM 페이지에 나타나면
Tempdb를 더 PATHLATCH_UP 대기, 당신은 래치 경합을 제거하기 위해 다음과 같은 방법을 수행 할 수 있습니다
임시 데이터베이스 데이터 파일은 코어 = CPU 번호의 수를 증가시키기 위해 < strong> 추적 플래그 (TF) 1118 사용
래치 Tempdb를 테이블 반환 함수이 때문에 PFS와 래치 경합이 같은 발생
충돌로 이어집니다. 모든 다중 문 테이블 반환 함수는 항상 래치 경합의 원인, 쿼리에 다중 문 테이블 반환 함수를 생성하고 테이블을 삭제하는 많은 변수를 탄생 될 수있는 다수의 참조 테이블 변수를 생성하고 삭제할 호출 .
다른 모드가 경합을 래치 해결 은행 ATM 시스템에서 ATM_ID 장면의 사용을 고려하여 처리합니다 INSERT 작업 테이블은 모든 주요 범위로 배포됩니다. 동시에, 사용자는 단지 하나의 ATM을 사용할 수 있기 때문이다. 이러한 장면은 Checkout_ID STORE_ID 열 또는 열을 사용하여 고려할 수, 시스템을 판매 할 예정이다. 이 방법은 고유 지수
이 방법은, 인덱스 조각화를 증가 스캔 성능의 범위를 감소시킬 것이다. 또한, 이러한 절 새로운 인덱스 구조에 따라 조정해야 WHERE 같이, 애플리케이션 아키텍처를 수정할 필요가있다. 예 : 트랜잭션 테이블에서 32 코어 시스템에서 원래의 테이블 구조 : 생성 테이블 표
( 왼쪽 는 TransactionId BIGINT 없습니다
널 (null) ( 아이디 INT 하지
널 (null)
에 대한 < /span> INT
없습니다 널 (null) )
표 추가
제약
pk_table1 < /span> 키
클러스터 (는 TransactionId, 아이디) 이동 1. 모든 데이터가 사용자 ID 첫 번째 키를 사용하기 위해 인덱스와 방법, 작업을 삽입하기 위해 배포됩니다 페이지. 주 : 인덱스 변경, 모든 선택이 방정식 ID와는 TransactionId를 지정해야합니다 WHERE합니다. 테이블
표 VALUES 는 TransactionId BIGINT 없습니다
널 (null) 표 아이디 INT 없습니다
없습니다
널 (null)
0 INT
없습니다 널 (null) )
이동 표 추가
제약
pk_table1 키
표
클러스터 (사용자 ID,는 TransactionId)
테이블 널 (null) 는 TransactionId 없습니다
int 아이디
(
널 (null) 1
SomeInt 없습니다
) 이동 - ( 표 추가 [ 2 ] TINYINT AS ALTER < /span> ( CONVERT 9 [] ] 3 ABS [< /span>
는 TransactionId ) %
( ))) PERSISTED NOT
변경 테이블 표
추가
이 방법은, 인덱스 조각화를 증가 스캔 성능의 범위를 감소시킬 것이다. 또한, 이러한 절 새로운 인덱스 구조에 따라 조정해야 WHERE 같이, 애플리케이션 아키텍처를 수정할 필요가있다. 예 : 트랜잭션 테이블에서 32 코어 시스템에서 원래의 테이블 구조 : 생성 테이블 표
( 왼쪽 는 TransactionId BIGINT 없습니다
널 (null) ( 아이디 INT 하지
널 (null)
에 대한 < /span> INT
없습니다 널 (null) )
표 추가
제약
pk_table1 < /span> 키
클러스터 (는 TransactionId, 아이디) 이동 1. 모든 데이터가 사용자 ID 첫 번째 키를 사용하기 위해 인덱스와 방법, 작업을 삽입하기 위해 배포됩니다 페이지. 주 : 인덱스 변경, 모든 선택이 방정식 ID와는 TransactionId를 지정해야합니다 WHERE합니다. 테이블
표 VALUES 는 TransactionId BIGINT 없습니다
널 (null) 표 아이디 INT 없습니다
없습니다
널 (null)
0 INT
없습니다 널 (null) )
이동 표 추가
제약
pk_table1 키
표
클러스터 (사용자 ID,는 TransactionId)
테이블 널 (null) 는 TransactionId 없습니다
int 아이디
(
널 (null) 1
SomeInt 없습니다
) 이동 - ( 표 추가 [ 2 ] TINYINT AS ALTER < /span> ( CONVERT 9 [] ] 3 ABS [< /span>
는 TransactionId ) %
( ))) PERSISTED NOT
변경 테이블 표
추가
제약
pk_table1
차
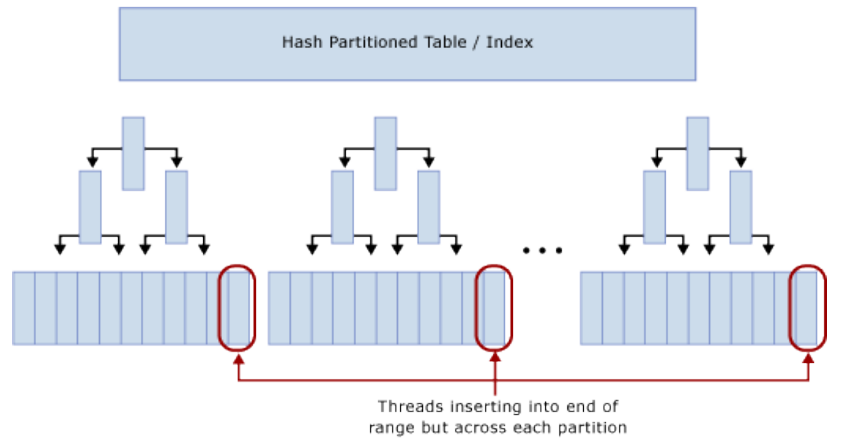
表分区能减少Latch争用。使用计算列对表进行Hash分区,一般的步骤:
- 키
- 클러스터
- (HashValue,는 TransactionId, 아이디)
이동
첫 번째 키 인덱스로 GUID 열을 사용하여
이 나는 난 아주 많이 여기의 무결성을 유지 플러스, 그것을 분석하고 싶지 않아, 동의하지 않습니다. 레디 스 제품을로드, 서브 테이블, 파티션을 배포 또는 사용하는 등 극단적 인 방법을 필요로 할만큼 심각한 동시로드 및 래치 경합 GUID는 더 나은 방법입니다. 테이블 해시 파티션의 계산 열을 사용하여 테이블 파티셔닝은 래치 경합을 줄일 수 있습니다. 테이블 해시 파티션의 계산 열, 일반적인 단계를 사용하여
새 또는 지구를 호스팅 기존의 파일 그룹을 사용하여 새 파일 그룹을 사용하는 경우, 당신은 데이터 입출력 서브 시스템 최적화 및 파일 그룹을 고려할 필요가 문서의 합리적 분배. INSERT 부하 비율이 높은 경우, CPU 코어의 1/4의 데이터 파일 그룹 추천 수 (또는 1/2와 같은 경우, 혹은 등전위가 될 수있다).
표는 N 개의 파티션으로 분할되어 파티션 함수를 만들 사용. N 값은 스텝 데이터 파일의 수와 동일하다. 파일 그룹에 결합 파티션 구성표를 만들 파티션 기능을 사용하고 해시 열의 SMALLINT 또는 TINYINT 유형을 추가 한 다음 해당 해시 분포 값 계산 (예를 들어 HashBytes 값 모듈에 대한 또는 Binary_Checksum 값을). 샘플 코드 : 파티션 방식과 기능을 생성, CPU 코어의 수를이 정렬 1 : 1까지 에 ( 코어 컴퓨터 ) 16 코어 시스템에 정렬이 아래에 대한 CREATE 있도록 파티션 pf_hash16
] (, ) , 범위 , , , (, , , , , , , 9, 4 , 5 , 6 , 7 , 8 , , ]
, 10 , 11 , , 13 [, (14) (15) CREATE ( 를 ps_hash16 ] < /span>
그대로 파티션
[ pf_hash16
] 모든 ] ( [ ALL_DATA 을 속도를 대량로드 기술을 사용하는 것이 좋습니다 ) -
(이 오프라인 작업입니다) 기존 테이블에 계산 된 열을 추가 ALTER ( DBO AS 0 [, ] 추가 [ HashValue [ ( CONVERT ( [
TINYINT ] ABS
(binary_checksum (Create the index on the new partitioning scheme
[ ] % (16) CREATE IX_Transaction_ID )))
PERSISTED CLUSTERED NULL - 새로운 분할 방식에 인덱스를 생성 ] < /span> UNIQUE ([ INDEX [, [ ON )
DBO ]
이 나는 난 아주 많이 여기의 무결성을 유지 플러스, 그것을 분석하고 싶지 않아, 동의하지 않습니다. 레디 스 제품을로드, 서브 테이블, 파티션을 배포 또는 사용하는 등 극단적 인 방법을 필요로 할만큼 심각한 동시로드 및 래치 경합 GUID는 더 나은 방법입니다. 테이블 해시 파티션의 계산 열을 사용하여 테이블 파티셔닝은 래치 경합을 줄일 수 있습니다. 테이블 해시 파티션의 계산 열, 일반적인 단계를 사용하여
새 또는 지구를 호스팅 기존의 파일 그룹을 사용하여 새 파일 그룹을 사용하는 경우, 당신은 데이터 입출력 서브 시스템 최적화 및 파일 그룹을 고려할 필요가 문서의 합리적 분배. INSERT 부하 비율이 높은 경우, CPU 코어의 1/4의 데이터 파일 그룹 추천 수 (또는 1/2와 같은 경우, 혹은 등전위가 될 수있다).
표는 N 개의 파티션으로 분할되어 파티션 함수를 만들 사용. N 값은 스텝 데이터 파일의 수와 동일하다. 파일 그룹에 결합 파티션 구성표를 만들 파티션 기능을 사용하고 해시 열의 SMALLINT 또는 TINYINT 유형을 추가 한 다음 해당 해시 분포 값 계산 (예를 들어 HashBytes 값 모듈에 대한 또는 Binary_Checksum 값을). 샘플 코드 : 파티션 방식과 기능을 생성, CPU 코어의 수를이 정렬 1 : 1까지 에 ( 코어 컴퓨터 ) 16 코어 시스템에 정렬이 아래에 대한 CREATE 있도록 파티션 pf_hash16
] (, ) , 범위 , , , (, , , , , , , 9, 4 , 5 , 6 , 7 , 8 , , ]
, 10 , 11 , , 13 [, (14) (15) CREATE ( 를 ps_hash16 ] < /span>
그대로 파티션
[ pf_hash16
] 모든 ] ( [ ALL_DATA 을 속도를 대량로드 기술을 사용하는 것이 좋습니다 ) -
(이 오프라인 작업입니다) 기존 테이블에 계산 된 열을 추가 ALTER ( DBO AS 0
TINYINT ] ABS
(binary_checksum (Create the index on the new partitioning scheme
[ ] % (16) CREATE IX_Transaction_ID )))
PERSISTED CLUSTERED NULL - 새로운 분할 방식에 인덱스를 생성 ] < /span> UNIQUE ([ INDEX [, [ ON )
DBO ]
.
[
latch_contention_table ![]()
]
(